Juan Antonio del Valle F.
Una cadena de Markov es una serie de eventos, en la cual la probabilidad de que ocurra un evento depende del evento inmediato anterior. En efecto, las cadenas de este tipo tienen memoria, "Recuerdan" el último evento y esto condiciona las posibilidades de los eventos futuros. Esta dependencia del evento anterior distingue a las cadenas de Markov de las series de eventos independientes, como tirar una moneda al aire o un dado. En los negocios, las cadenas de Markov se han utilizado para analizar los patrones de compra,los deudores morosos, para planear las necesidades de personal y para analizar el reemplazo de equipo. El análisis de Markov, llamado así en honor de un matemático ruso que desarrollo el método en 1907, permite encontrar la probabilidad de que un sistema se encuentre en un estado en particular en un momento dado. Algo más importante aún, es que permite encontrar el promedio a la larga o las probabilidades de estado estable para cada estado. Con esta información se puede predecir el comportamiento del sistema a través del tiempo. La tarea más difícil es reconocer cuándo puede aplicarse. La caracteristica más importante que hay que buscar en la memoria de un evento a otro.Considere el problema siguiente: la compañía K, el fabricante de un cereal para el desayuno, tiene un 25% del mercado actualmente. Datos del año anterior indican que el 88% de los clientes de K permanecían fieles ese año, pero un 12% cambiaron a la competencia. Además, el 85% de los clientes de la competencia le permanecían fieles a ella, pero 15% de los clientes de la competencia cambiaron a K. Asumiendo que estas tendencias continúen determine
¿cual es la parte que K aprovecha del mercado?:en 2 años; y
en el largo plazo.
Esta situación es un ejemplo de un problema de cambio de marcas que sucede muy a menudo que se presenta en la venta de bienes de consumo.
Para resolver este problema hacemos uso de cadenas de Markov o procesos de Markov (qué es un tipo especial de proceso estocástico). El procedimiento se da enseguida.
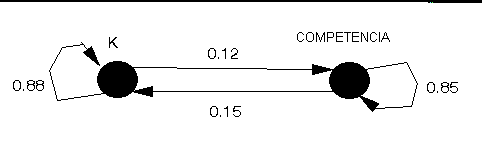
Observe que, cada año, un cliente puede estar comprando cereal de K o de la competencia. Podemos construir un diagrama como el mostrado abajo donde los dos círculos representan a los dos estados en que un cliente puede estar y los arcos representan la probabilidad de que un cliente haga una cambio cada año entre los estados. Note que los arcos curvos indican una "transición" de un estado al mismo estado. Este diagrama es conocido como el diagrama de estado de transición (notar que todos los arcos en ese diagrama son arcos dirigidos).
Dado ese diagrama nosotros podemos construir la matriz de la transición (normalmente denotada por el símbolo P) la qué nos dice la probabilidad de hacer una transición de un estado a otro estado. Sea:
estado 1 = cliente que compra cereal de K y
estado 2 = cliente que compra cereal de la competencia
tenemos así la matriz de transición P para este problema, dada por
Para estado 1 2
Del estado 1 | 0.88 0.12 |
2 | 0.15 0.85 |
Note aquí que la suma de los elementos en cada fila de la matriz de la transición es uno.
Por datos de este año sabemos que actualmente K tiene un 25% del mercado. Tenemos que la fila de la matriz que representa el estado inicial del sistema dada por:
Estado
1 2
[0.25, 0.75]
Normalmente denotamos esta fila de la matriz por s1 indicando el estado del sistema en el primer periodo (años en este ejemplo en particular). Ahora la teoría de Markov nos dice que, en periodo (año) t, el estado del sistema está dado por el st de la fila de la matriz, donde:
st = st-1(P) =st-2(P)(P) = ... = s1(P)t-1
Tenemos que tener cuidado aquí al hacer la multiplicación de la matriz ya que el orden de cálculo es importante (i.e. st-1(P) no es igual a (P)st-1 en general). Para encontrar st nosotros podríamos intentar hallar P directamente para la potencia t-1 pero, en la práctica, es mucho más fácil de calcular el estado del sistema en cada sucesivo año 1,2,3 ,..., t.
Nosotros ya sabemos el estado del sistema en el año 1 (s1) tal que el estado del sistema en el año dos (s2) está dado por:
s2 = s1P
= [0.25,0.75] |0.88 0.12 |
........|0.15 0.85 |
= [(0.25)(0.88) + (0.75)(0.15), (0.25)(0.12) + (0.75)(0.85)]
= [0.3325, 0.6675]
Note que este resultado tiene sentido intuitivo, e.g. del 25% comprando actualmente al cereal de K, 88% continúan haciendolo, aunque del 75% comprando el cereal del competidor 15% cambia a comprar cereal de K - dando un (fracción) total de (0.25)(0.88) + (0.75)(0.15) = 0.3325 comprando cereal de K.
De lo anterior, en el año dos 33.25% de las personas están en estado 1 - esto es, está comprando cereal de K. Note aquí que, como un chequeo numérico, los elementos de st deben sumar siempre uno.
En el año tres el estado del sistema se da por:
s3 = s2P
= [0.3325, 0.6675] |0.88 0.12 |
............... |0.15 0.85 |
= [0.392725, 0.607275]
Por lo tanto en el año tres 39.2725% de las personas están comprando al cereal de K.
Recalcar que está pendiente la cuestión hecha sobre la porción que K comparte del mercado en el largo plazo. Esto implica que necesitamos calcular st cuando t se hace muy grande (se acerca al infinito).
La idea de la largo plazo es basada en la suposición de que, en el futuro, el sistema alcance un "equilibrio" (a menudo llamado el "estado sustentable") en el sentido de que el st = st-1. Ésto no quiere decir que las transiciones entre estados no tengan lugar, suceden, pero ellos tienden "al equilibrio global" tal que el número en cada estado permanece el mismo.
Hay dos enfoques básicos para calcular el estado sustentable:
Computational: - encontrar el estado sustentable calculando st para t=1,2,3,... y se detiene cuando st-1 y st son aproximadamente el mismo. Esto es obviamente muy fácil para una computadora y este es el enfoque usado por un paquete computacional.
Algebraico: - para evitar cálculos aritméticos largos necesarios para calcular st para t=1,2,3,... tenemos un atajo algebraico que puede usarse. Recalcar que en el estado sustentable st = st-1 (= [x1,x2] para el ejemplo considerado anteriormente). Entonces como st = st-1P tenemos eso
[x1,x2] = [x1,x2] | 0.88 0.12 |
.............| 0.15 0.85 |
(y también notar que x1 + x2 = 1). De esto tenemos tres ecuaciones que podemos resolver.
Note aquí que hemos usado la palabra suposición anteriormente. Esto es porque no todos los sistemas alcanzan un equilibrio, esto es, no cualquier sistema tiene matriz de transición
| 0 1 |
|1 0 |
nunca alcanza un estado sustentable.
Adoptando el enfoque algebraico anteriormente para el ejemplo del cereal K tenemos las tres ecuaciones siguientes:
x1 = 0.88x1 + 0.15x2
x2 = 0.12x1 + 0.85x2
x1 + x2 = 1
o
0.12x1 - 0.15x2 = 0
0.12x1 - 0.15x2 = 0
x1 + x2 = 1
Note que la ecuación x1 + x2 = 1 es esencial. Sin élla no podríamos obtener una única solución para x1 y x2. Resolviendo conseguimos x1 = 0.5556 y x2 = 0.4444
Por lo tanto, en la largo plazo, K comercializa una porción del mercado del 55.56%.
Un chequeo numérico útil (particularmente para problemas más grandes) es sustituir el examen final calculando los valores en las ecuaciones originales para verificar que ellos son consistentes con esas ecuaciones.
Paquete de Computo para la solución
El problema anterior se resolvió usando un paquete, la entrada se muestra abajo.
Datos de entrada del Problema del cereal de K (Iniciales Probabilidades de Estado)
1: 0.2500 2: 0.7500
Datos de entrada del Problema del cereal de K (Matriz de Probabilidades de Transición) Pg 1
.......De ...........A
1 1: 0.8800 2: 0.1200
2 1: 0.1500 2: 0.8500
El rendimiento se muestra debajo. Aunque el paquete puede usarse para calcular y desplegar st (para cualquier valor de t) no hemos querido mostrar esto.
En el rendimiento mostrado abajo de la nota:
las probabilidades de estado sustentables (se necesitaron 38 iteraciones antes de que st-1 y st fueran aproximadamente el mismo). Estas figuras son como se calcularon antes.
periodo recurrente para cada estado - éstos son el número esperado de periodos que pasarán para que una persona en un estado esté de nuevo en ese estado (esto es, esperaríamos que hubieran 1.80 periodos (en promedio) entre que una persona que compra el cereal de K y su próxima compra de cereal de K).
Iteración final--las Iteraciones Totales = 38
1: 0.5556 2: 0.4444
Periodo recurrente para Cada Estado
1: 1.80 2: 2.25
Datos
Note aquí que los datos que pueden necesitarse para deducir las probabilidades de transicióna, pueden a menudo fácilmente encontrarse, hoy en día . Por ejemplo se colectar tales datos por marca del consumidor que cambia, inspeccionando a los clientes individualmente. Sin embargo hoy día, muchos supermercados tienen sus propias "tarjetas de lealtad" qué son registradas a través de inspecciones al mismo tiempo que un cliente hace sus compras en la caja. Éstos proporcionan una masa de información detallada sobre el cambio de marca, así como también otra información - por ejemplo el efecto de campañas promocionales.
Debe estar claro que las probabilidades de transición no necesitan se consideradas como números fijos - más bien ellas son a menudo números que podemos influenciar/cambiar.
También note que la disponibilidad de tales datos permite modelos más detallados, al ser construidos. Por ejemplo en el caso del cereal, la competencia fue representado por sólo un estado. Con datos más detallados ese estado pudiera ser desagregado en varios estados diferentes - quizá uno para cada marca competidora del cereal. También podríamos tener modelos diferentes para segmentos diferentes del mercado - quizá el cambio de marca es diferente en áreas rurales del cambio de marca en áreas urbanas, por ejemplo. Las familias con niños constituirían otro segmento importante del mercado obviamente.
Cualquier problema para el que puede obtenerse un diagrama de transición de estado y que usa el enfoque dado puede analizarse.
Las ventajas y desventajas de usar teoría de Markov incluyen:
Una aplicación interesante de procesos de Markov que yo conozco es la industria costera noruega del petroleo/gas. En Noruega un cuerpo estatal, el Consejo de administración de Petróleo noruego, (junto con la compañía de aceite estatal noruega (STATOIL)), tienen un papel grande en la planeación de los medios para el desarrollo costero del petroleo/gas.
El problema esencial que el Consejo de la administración del Petróleo noruego tiene, es cómo planear la producción para aumentar al máximo su contribución en el tiempo a la economía noruega. Aquí los horizontes de tiempo son muy largos, típicamente 30 a 50 años. De importancia crítica es el precio del aceite - todavía nosotros no podemos prever esto, sensiblemente con exactitud, para esta horizonte de planeación.
Para superar este problema ellos modelan el precio del aceite como un proceso de Markov con tres niveles de precio (estados), correspondiendo a escenarios optimista, probable y pesimista. Ellos también especifican las probabilidades de hacer una transición entre los estados cada periodo de tiempo (año). Pueden usarse matrices de transición diferentes para horixzontes de tiempo diferentes ( matrices diferentes para el cercano, medio y futuro lejano).
Aunque éste simplemente es un enfoque simple, tiene la ventaja de capturar la incertidumbre sobre el futuro en un modelo que es relativamente fácil de entender y aplicar.
Estudios sobre el modelado de la población (donde nosotros tenemos objetos con "edad") también son una aplicación interesante de procesos de Markov.
Un ejemplo de esto sería el modelado el mercado del automóvil como un proceso de Markov para prever la "necesidad" de nuevos automóviles cuando los automóviles viejos puedan extínguirse.
Otro ejemplo sería modelar el progreso clínico de un paciente en hospital como un proceso de Markov y ver cómo su progreso es afectado por régimenes de droga diferentes.
TAREA: DESCRIBIR UNA APLICACION PARA LA INGENIERIA CIVIL